Entraîner l’IA pour la génomique : le premier jeu de données standardisé
Source(s): Genopole
Le laboratoire IBISC (Informatique, BioInformatique, Systèmes Complexes) de l’Université d’Évry a construit le premier jeu de données standardisé sur des structures d’ARN non codants. L’objectif de ce jeu est de fournir aux chercheurs en apprentissage automatique, une des branches de l’intelligence artificielle, les moyens d’entraîner leurs modèles et d’accélérer les recherches dans ce domaine d’intérêt […]
Le laboratoire IBISC (Informatique, BioInformatique, Systèmes Complexes) de l’Université d’Évry a construit le premier jeu de données standardisé sur des structures d’ARN non codants.
L’objectif de ce jeu est de fournir aux chercheurs en apprentissage automatique, une des branches de l’intelligence artificielle, les moyens d’entraîner leurs modèles et d’accélérer les recherches dans ce domaine d’intérêt majeur.
L’apprentissage automatique, qu’est ce que c’est ?
L’apprentissage automatique ou machine learning, est une méthode d’intelligence artificielle qui consiste à créer des modèles mathématiques capables d’améliorer leurs performances en « s’entraînant » sur des données, en « apprenant » progressivement et en ajustant le modèle en fonction des réponses. L’approche démontre son potentiel en sciences du vivant, notamment pour l’exploitation des données massives et complexes issues du séquençage des génomes et autres données moléculaires.
La recherche appliquée en apprentissage automatique progresse donc plus rapidement lorsqu’un jeu de données exploitables est disponible et prêt à l’emploi.
Le premier jeu de données standardisé de structures d’ARN non codants
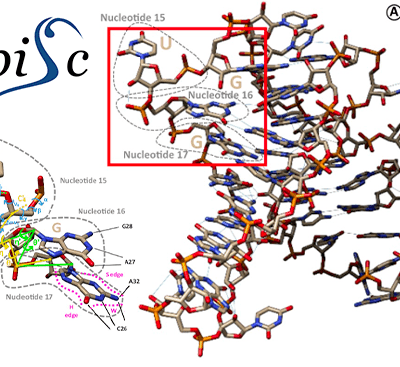
L’équipe AROB@S (Algorithmique, Recherche Opérationnelle, Bioinformatique et Apprentissage Statistique) du laboratoire IBISC, Université d’Évry, propose le premier jeu de données standardisé de structures d’ARN non codants, construit automatiquement à partir des données publiques. Il combine des séquences d’ARN, des informations d’homologie entre séquences (alignements, fréquences des mutations, appartenance à une famille de molécules), et des informations disponibles sur les structures 3D (contacts entre nucléotides distants, descripteurs géométriques de la chaîne de nucléotides).
Le jeu de données est utilisable dans différentes applications bioinformatiques d’apprentissage et de « data mining », comme l’entraînement de modèles statistiques pour prédire les structures des ARN non codants, les interactions avec d’autres macromolécules, la classification en familles d’ARN, ou la construction de bibliothèque de motifs structuraux.
Vous pouvez retrouver ce jeu sur le site de la plateforme EvryRNA.
Lire l’article sur le site web de Genopole
En savoir +